How is AI Impacting Modern Data Teams?
AI is all over the news. You can’t go a single day without seeing, thinking about, or using AI in your everyday life. Generative AI is all the rage and accounts for much of the value creation (or speculation) in the market, however that is not the only form of AI that can increase productivity and business outcomes. Below, I outline how artificial intelligence is impacting data teams today. Its impacts span all pillars of data teams—data engineering, data analysis, business intelligence, and data science.
AI for Data Engineering and Analysis
Data engineers and analysts now have a wide range of tools and methods at their fingertips to make their jobs more efficient. The tools available span from assisting the more mundane parts of their job, such as documentation of models/processes, to the integral parts of the job function, such as setting up data pipelines, optimizing code, and minimizing compute costs.
It is standard practice within any reputable organization for data engineers and analysts to thoroughly document their data models. For starters, it will allow technical users to understand the purpose and logic behind the code. Moreover, this allows the organization to have a repository for business metrics and the source of truth for those metrics. As an engineer or analyst is working through a data model, they should ensure to comment liberally about what each step is doing and/or make the names of their tables, CTEs, and variables explicitly clear. Then, the individual can paste that code into your Gen AI product of choice, such as Gemini, and ask it to generate (1) documentation for the code and (2) a .yaml file with the model/variable descriptions.
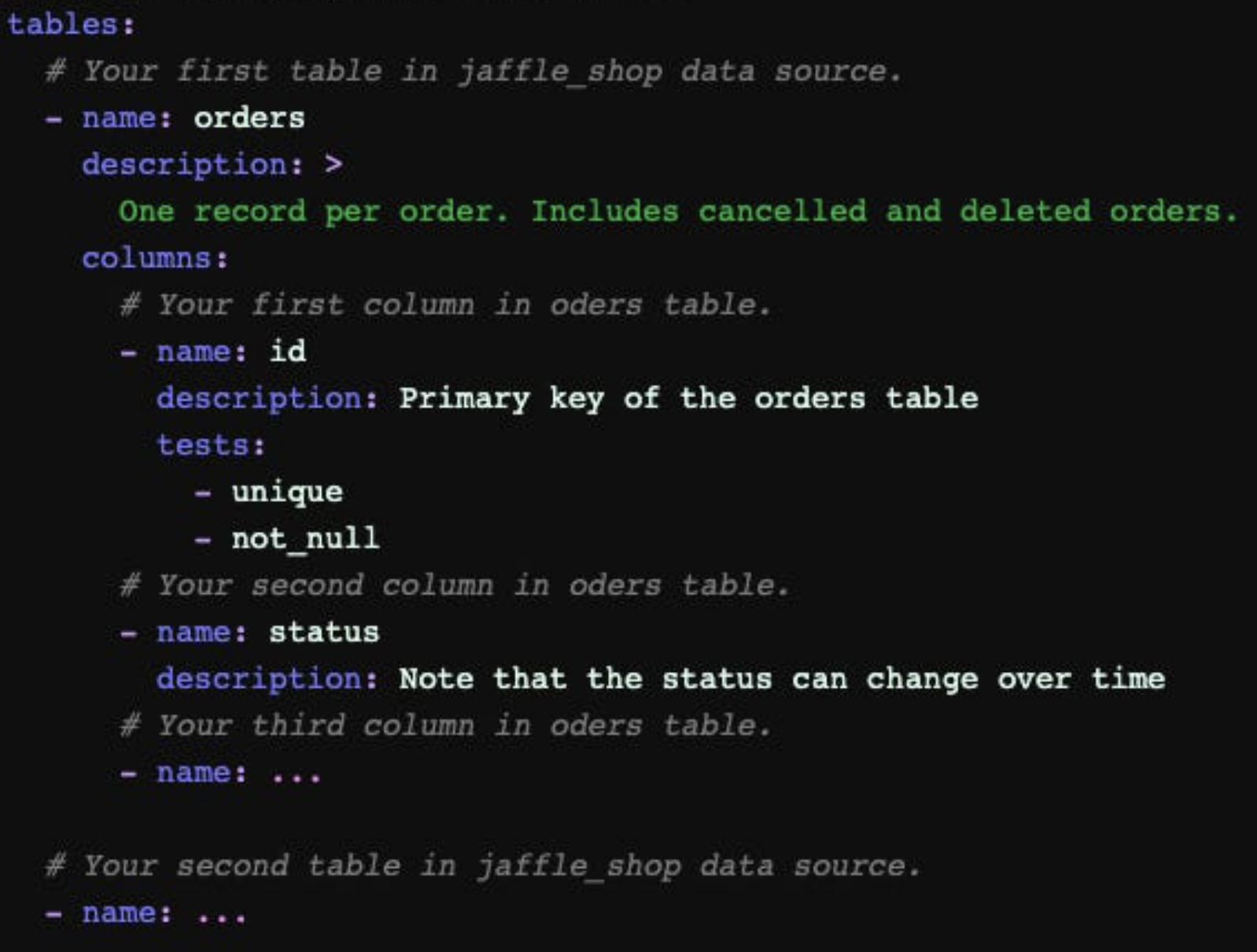
This is a simple “.yaml” file that specifies the purpose of the model as well as the definitions for each of the variables. This integrates into dbt documentation, so you can easy search for this information in a company’s data catalog.
All data analysts and engineers should be using Cursor if they aren’t already. Cursor is an AI tool that integrates directly into most development platforms and helps you code. There are two main features that you get access to: Tab and Agent. Within the “Tab” feature, developers are able to leverage powerful autocomplete whilst coding. For example, you may comment at the top of a code block that says -- Group by user and month, count orders, revenue, and average order value and once you begin coding that section it will easily autocomplete the code to:
SELECT
user
, month
, COUNT(DISTINCT order_id) AS total_orders
, SUM(revenue) AS total_revenue
, total_revenue / total_orders AS average_order_value
FROM orders
GROUP BY ALLSure, that’s a very easy query to conjure up, but this tool is very powerful. No matter how tenured you are at a company, you’ll frequently forget table names and fields contained in those tables. Cursor’s Tab autofills tables that you may be looking for and the specific variables you want. It seems like a simple functionality that should’ve been available to most data analysts years ago, however this is the first of its kind. Snowflake felt the pressure and just released a similar, albeit weaker, tool to their UI this week.
Where Cursor really excels is in its “Agent” product. This allows users to explain a data task that they want to outsource to Cursor’s “Human-AI” tool and it will generate a script for them. In the example code block above, the user may just ask “generate an aggregation of unique orders, revenue, and average order values by user and month,” which would spit out a .sql file with the code above. It does this by connecting your data warehouse to an LLM model (Gemini, ChatGPT, Claude). This saves an immense amount of time for data analysts trying to answer ad hoc questions from non-technical stakeholders.
While this is an extremely powerful software, it does come with significant risk, if not set up correctly. You can’t just hook this up to the full data warehouse because there may be numerous “orders” tables that have slightly different types of orders and fields included. This will result in the LLM generating different SQL, and subsequently different results, depending on which orders table it references. This can cause more problems than it solves if you just feed ungoverned and unstructured data into the model, as you will lose stakeholder confidence in the data products, possibly even generate incorrect insights, which could cause business misdirection. Leveraging Cursor requires diligent care and data hygiene from the data engineering team to operate correctly.
A Text to Solution Tool
Similar to Cursor’s Agent product, there are now full text to visualization tools. Hex enables all users to generate immediate insights, irrespective of their technical background. You might ask Hex, “what was revenue by month from 2023 to 2025 for users acquired through paid marketing channels?” Hex will generate a chart for you showing exactly what you asked.
Again, tools like Hex are amazing, however it is imperative that it only relies on a curated set of data sources. It is even more important for a text-to-solution tool for there to be strict data governance than a tool like Cursor, specifically because the end consumers will be non-technical. They will not be able to debug a query or even tell if it is giving them incorrect information.
I see these products as being a massive threat to pure “Business Intelligence Analysts” whose primary responsibility is creating dashboards for business stakeholders. Right now, these analysts are basically serving as a middleman between data engineers/analysts and non-technical stakeholders. If the engineers are able to adequately expose and train the LLM models on the proper pool of data, there is effectively no need for this role. There is an argument to be made for the beautification of visuals that these BI Analysts can provide, but my counter is that pretty much anyone can be trained to choose the right visuals and formatting. Moreover, data analysts, whose responsibilities cover more than just dashboarding, can just step in to do due diligence on the generated insights from the platform.
How is it impacting Data Science?
At this juncture, I think that many higher-level analytics tasks, and data science tasks are safe from AI. That being said, these employees should leverage AI tools to maximize their efficiency. As noted before, data scientists and analysts should use Cursor and Hex to optimize their time spent coding and debugging with autocomplete features.
While Data Scientists may leverage ML models, I don’t think it is realistic, at this point, to have AI replace those data scientists who deploy these models. A human is able to gather insights from the end stakeholders (i.e. the consumers of the model), whereas the AI will only be able to use what it is trained on.
For example, a data scientist may be building a classification model to bucket orders into “fraud” or “not fraud.” An LLM would surely be able to build a reasonable model, finding obvious features for identifying fraudulent orders:
Fraudulent phone numbers
First orders are more likely to be fraudulent
Email character patterns, specifically with personal email domains
How many cards the user has tried to validate/charge
Among other clustering variables
Though, through speaking with the payments & fraud team, a human may learn a lot of potential features to include in the model, such as:
Keeping a repository of known fraudulent phone numbers and addresses
Reading in supplemental first (i.e. customer service chats) and third-party (i.e. residential address flags) data sources
Additionally, a human is needed to interpret these results and explain them to stakeholders to gain trust in the model. In many instances, a highly-interpretable model is necessary so business partners can understand what is the feature importance and what is actually driving these predictions. An LLM will not be taking that into consideration unless you explicitly tell it to try a logistic regression or Naive Bayes (or some other model where you can isolate feature importance). And if you need to do that, you can’t eliminate your valuable data scientists! Because they will have the skills to determine the correct model to use and how to measure the accuracy!
I think we are at a point where AI and ML models are significantly helping data scientists to (1) become more efficient and (2) build more accurate models. Although, I do not think that these roles are anywhere close to being eliminated due to the specificity and deep quantitative background required to provide value in these roles. ML models cannot be easily synthesized into reasoning by a non-technical employee.
The Future: Productivity Boosts to Strategic Autonomy
As noted above, AI is already impacting every facet of a data team and its procedures. There are still many areas where I think the technology will have a material influence on how these teams operate in the near future.
Self-Healing Data Stacks: AI will move beyond building models to managing them. Imagine an autonomous layer that identifies unused reports or costly, redundant models and sunsets them automatically. For large organizations, this data hygiene automation could easily save north of $1 million annually in compute and storage costs.
Domain-Specific AI Concierges: We will move away from generic "ask anything" bots toward specialized business domain experts. Instead of one Slackbot for all of Amazon, imagine dedicated agents for B2C, B2B, or Prime Video. These bots will be trained on curated data marts specific to their niche, ensuring that when you ask for "yesterday's orders," you get the exact number relevant to your business unit, not a company-wide hallucination.
One-Prompt Insights: The days of waiting weeks for a dashboard are numbered. By exposing LLMs to governed, structured data, stakeholders will be able to generate complex analyses, like measuring the revenue impact of a 5-hour site outage, in minutes. While human logic will still be needed to account for nuances like "deferred demand," (i.e. how many of those customers would return to place the order rather than going to a competitor) AI will provide the 90% starting point that currently consumes most of an analyst's time.
Ultimately, humans will always be needed to synthesize business context to feed to these tools, so I don’t think that AI will ever fully replace data teams or any specific layer within these teams. My opinion is that business intelligence analysts, whose primary function is to build dashboards and reporting for stakeholders, are the most exposed to the impacts of AI. We are already at a point where many of these positions can be replaced, as AI can answer most ad hoc questions from stakeholders, conditional upon the data being structured appropriately and, more importantly, the data being accurate.
Well-rounded data analysts and data engineers have the most insulation because so much of their job function depends on critical thinking and synthesizing business logic into code.